
컨퓨전 매트릭스(Confusion Matrix)는 머신 러닝에서 분류 모델의 성능을 평가하기 위해 사용되는 표 입니다. 실제 값(정답, Ground Truth)과 예측 값(Predicted Value)을 비교하여 모델의 예측 결과를 상세히 분석할 수 있도록 도와줍니다. 이 행열은 모델이 어떤 종류의 오류를 발생 시키는지 파악하고 다양한 성능 지표를 계산하는 데 유용합니다.
Confusion Matrix의 구조
이진 분류(Binary Classification)의 경우, Confusion Matrix는 다음 4가지의 주요 구성 요소로 이루어져 있습니다.
|
실제 값 / 예측 값
|
긍정 (Positive, 예측 값)
|
부정 (Negative, 예측 값)
|
|
긍정 (Positive, 실제 값)
|
True Positive (TP)
|
False Negative (FN)
|
|
부정 (Negative, 실제 값)
|
False Positive (FP)
|
True Negative(TN)
|
- True Positive (TP) : 실제로 긍정인 데이터를 모델이 올바르게 긍정으로 예측한 경우.
- False Positive (FP) : 실제로 부정인 데이터를 모델이 잘못 긍정으로 예측한 경우.
- False Negative (FN) : 실제로 긍정인 데이터를 모델이 잘못 부정으로 예측한 경우.
- True Negative(TN) : 실제로 부정인 데이터를 모델이 올바르게 부정으로 예측한 경우.
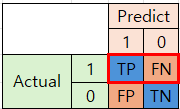
표로 나타내면 아래와 같습니다. 이러한 형태를 Confusion Matrix라고 합니다.
|
|
Predict
|
||
|
1
|
0
|
||
|
Actual
|
1
|
TP
|
FN
|
|
0
|
FP
|
TN
|
|
Confusion Matrix를 통해 계산할 수 있는 주요 지표
1. 정확도(Accuracy) : 전체 데이터 중 올바르게 예측한 비율을 측정합니다.
2. 정밀도(Precision) : 긍정적으로 예측한 데이터 중 실제로 긍정인 데이터의 비율을 측정합니다.
3. 재현율(Recall, 민감도) : 실제로 긍정인 데이터 중 모델이 올바르게 긍정을 예측한 비율을 측정합니다.
4. F1점수(F1 Score) : 정밀도와 재현율의 조화를 측정하는 지표입니다.
예시
간단한 예시를 들어보겠습니다. 아래 표는 10개의 Data와 그에 대한 예측 결과를 나타냅니다.

위의 표에서 각 index에 대한 결과는 아래와 같습니다.

- TP : 3개, (4,5,7)
- TN : 2개, (2,3)
- FP : 3개, (1,8,9)
- FN : 2개, (6,10)
그럼 이를 이용하여 Confusion Matrix는 쉽게 만들 수 있습니다.

위의 예시에서 계산해보면 아래와 같습니다.
정확도(Accuracy)

정밀도(Precision)

재현율(Recall)
F1점수 (F1 Score)
활용사례
Confusion Matrix는 다양한 분야에서 활동됩니다.
- 의료 진단 : 질병 감지에서 False Negative를 최소화하는것이 중요합니다(예: 암진단).
- 사기 탐지 : False Positive를 줄여 불필요한 조사 비용을 절감합니다.
- 스팸 필터링 : 정밀도와 재현율 간의 균형을 맞춰 효과적으로 스팸 이메일을 걸러 냅니다.
결론
Confusion Matrix는 분류 모델의 성능을 세부적으로 분석할 수 있는 강력한 도구 입니다. 이를 통해 모델의 강점과 약점을 파악하고, 다양한 성능 지표를 활용하여 모델을
개선할 수 있습니다.
글쓴이 : 두루이디에스 SW공인시험팀, 한윤환 책임 연구원
'AI 자동화 연구소 > Column' 카테고리의 다른 글
| [Playwright #1] Playwright 소개 및 설치 방법 (3) | 2025.07.08 |
|---|---|
| 2편 MCP(Model Context Protocol) 아키텍처와 구성요소 (1) | 2025.07.08 |
| 1편 MCP(Model Context Protocol)란 무엇인가? (0) | 2025.07.08 |
| 💼 AI 인재 전쟁 본격화 – 2025년 기업들이 찾는 AI 인재는? (3) | 2025.06.27 |
| rPPG에 대한 기술의 혁신과 미래 (4) | 2025.04.08 |